- Reseller Advocate Magazine Circa 2008 -
RAM was a publication aimed at System Builders and resellers. Subscription was free to qualifed applicants.
Press Release
Sep 10, 2008 - Reseller Advocate Magazine (RAM) Dies Another one bites the dust. Reseller Advocate Magazine's (RAM) current issue comes with a cover stating "We Quit On Print." Why is RAM getting out of the print magazine business and switching to the web? There's the spin, and then there's basic dollars and cents.
A quote from Publisher John Martinez on RAM's magazine cover states:
"It doesn't make sense to do print anymore in a time of skyrocketing costs, severe environmental issues, and the tremendous amount of opportunities available in today's broadband world."
RAM is done with print. But apparently, RAM will live on at www.reselleradvocate.com.
For a number of years this was the Reseller Advocate Magazine's website. There were over 72 back issues available on the site.
The domain's registration eventually expired. The new owner has chosen to create this one web page with content is from the magazine's 2008 archived pages to provide just a few examples of what this site offered its readership.
Cover Story

"Our agency was one of the groups that bought space on the original print version of the magazine. One of our clients experienced an excellent sales bump due to the fact that their products - glasses and replacement lenses - lined up with the demographics of this publication. And there was a great deal of demand for accurate & detailed glasses information, especially on the types of lenses. The most successful campaign was for computer glasses, where the product completely lined up with many of the themes published in every issue. Many people don't even realize that there is such a thing as computer glasses - these are glasses designed to focus in between distance and close up - the place where most people view their computer. While we are sad to see the publication leave the print world, we intend to continue to support the effort with clients whose interests align with the topics covered. Very good buy for many retailers in overlapping markets!" Jon Hunt, AGF Marketing
"Few observers of this industry acurately predicted the rapid move from print to internet publishing. One of those who not only saw it coming, but also contributed to the acceleration of the migration was TNG/Earthling's CEO Bob Sakayama. His expertise was in exploiting high ranks in organic search results to generate hightly targeted traffic to his and his client's websites. TNG/E helps clients rank for their valuable keywords in Google searches which is a powerful new means of gaining visibility. Many credit this process with motivating the switch to the new media which was only accelerated by the smart phone and the rise of Google." Hudson Smythe, Doomsday
Shanghai Noon
By DiaNna Rao
We all know the great Western showdown clichés. Tumbleweeds. Sweat. People fleeing from the dusty streets as two gun-packing opponents face off under a merciless sun. Odds are good that one of them will be bruised and bleeding, barely able to stand. Somewhere, a soundtrack whistles a forlorn, warbling tune. Fingers twitch. No one breathes. It’s Shanghai time.
Without question, 2008 was one of the most challenging years in AMD’s four decades. The long-anticipated launch of K10 architecture, better known as Barcelona, struggled from the outset for several reasons, many of which had more to do with manufacturing issues than the product’s fundamental architecture. Barcelona was and remains an excellent desktop and server processor. However, competition from Intel soon exposed the performance holes in AMD’s release. Saddled with a 65nm fab process, Barcelona struggled to scale in frequency and was limited in cache size, even though—like a little Western town waiting for gold to be found in the hills—the underlying design was capable of much more.
At last, the promise of Barcelona is reaching fruition. AMD took its native quad-core flagship, applied a 45nm fab shrink to it, made several important additions, and code-named the results Shanghai. We know that Barcelona left a bad taste in many mouths. From early availability problems to trouble with frequency scaling, Barcelona was often the microarchitecture that could’ve, should’ve, and didn’t. (Of course, Barcelona priced right in the low- and mid-range markets can still be a screaming good value.) Shanghai now fulfills the Barcelona promise. If you and your customers blew off Barcelona, try shifting to Shanghai. You’ll find it’s well worth the time.
Barcelona Benefits
At the end of a punishing year—OK, two years—for AMD, it’s easy to lose sight of all the things that made Barcelona an excellent product. For starters, there’s the unified quad-core design. AMD was never shy about criticizing Intel’s use of two dual-core dies in one CPU package rather than having a single, unified die with four cores on it. AMD long maintained that requiring core 1 in the left die to communicate with core 3 or 4 in the right die via a front-side bus connection that wended all the way to the northbridge and back was inefficient at best . . . which is true. Nobody disputes that, all other things being equal, a unified design is better.
For better or worse, though, all other things weren’t equal. Intel has almost always had the benefits of faster clock speeds and much larger L2 caches to help mitigate its front-side bus latencies. So ultimately, which architecture was better for the customer often boiled down to which resources the application emphasized. If the app relied heavily on frequency speeds and cache, Intel usually won. If the app leaned more on memory, the needle often shifted to Barcelona because the CPU had a direct connection to RAM through a memory controller embedded in the processor. Historically, Intel always required more memory delays because RAM could only be accessed through the shared front-side bus and the northbridge’s memory controller. This is one reason why AMD has had so much success with heavily virtualized servers, which require very fast memory performance.
How AMD-V Stacks Up.
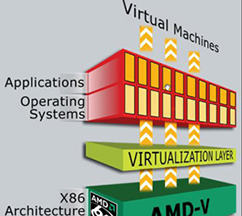
The collection of CPU optimizations known as AMD-V works with the hypervisor to accelerate the switching time between virtual machines.
AMD’s more flexible alternative to the front-side bus is called HyperTransport, and it’s been in use since the Athlon XP. Whereas the front-side bus only connects CPUs to the northbridge, HyperTransport interlinks CPUs, core logic components, and memory. Taken together, AMD calls this web ofHyperTransport links Direct Connect Architecture (DCA), and it’s the foundation of Opteron’s rocket ride to success in the first half of this decade.
The pre-Barcelona, dual-core Opteron Revision F used a 64KB L1 cache in each core backed by a 2x1MB L2, meaning 1MB of L2 cache for each core. You probably know that the purpose of cache is to keep recently or soon-to-be-needed (as guessed by algorithmic prediction) memory data as close to the processor cores as possible so as to avoid lengthy seeks to RAM. The smaller the cache, the faster it can be searched, which is why CPU designers use multiple cache tiers. When the CPU has a memory request, it first searches the L1. If there is no hit for the data in L1 (better known as a cache “miss”), the search proceeds to L2, and so on, all the way out to system memory if necessary.
With quad-core Barcelona, AMD kept 2MB of total L2 on the chip, dividing it into 512KB dedicated to each core. But Barcelona then added a shared 2MB L3. AMD believes that a shared L3 topped by smaller, dedicated L2 blocks makes for a more scalable, ultimately higher-performing design. AMD notes that L3 cache helps applications share multi-tasked data across multiple processor cores rather than circle back to ping each individual core. Apparently, this is another instance of AMD engineers beating Intel to the punch, because Intel’s Nehalem made a move very similar to Barcelona, downsizing the L2 and introducing a larger L3, bringing it to market a year and a half after AMD.
Beyond fundamental architectural changes, Barcelona introduced several new energy-saving features. First among these is split power planes, or Dual Dynamic Power Management, which established separate power feeds to the CPU cores and memory. Segregating these allowed CPU cores to enter lower power states while leaving full voltage and frequency to the memory and vice versa. On top of pre-existing PowerNow! Technology, Independent Dynamic Core Technology automatically adjusts the frequency of each core to lower the power draw on underutilized cores. Getting even more granular, AMD CoolCore technology could dynamically and quickly (within one clock cycle) turn off sections of each CPU die in order not to waste power on logic blocks that didn’t need to be active.
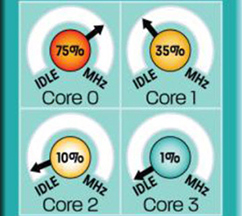
Minds of Their Own.
Each Barcelona (and Shanghai) core has the ability to modify its own frequency according to system demand. This results in far less power consumption under normal conditions.
We want to review these points for two reasons. First, to lay some of the groundwork for the features that all carry forward into Shanghai. Second, to remind you that Barcelona remains a very strong offering. The chip may not have lived up to everyone’s wildest expectations, but that doesn’t mean that Barcelona still doesn’t have a lot of value to offer.
A Shanghai Surprise?
It’s probably fair to call the first “Multi-Core” Opterons (meaning the original dual-core designs introduced in 2005) a revolution. Going from decades of single-core designs to an integrated dual-core is a pretty massive step. From there, going to a unified quad-core chip, Barcelona, is impressive if not quite as groundbreaking. So to say that Shanghai is anything more than an impressive evolution would be misleading. By and large, Shanghai is the same as Barcelona, only better. There are no major surprises, but the iterative improvements made across the board add up to a product with significantly more value. Let’s explore how and why Shanghai is better in order for you to illustrate the new processor’s merits to customers.
The 45nm Move
A fab shrink is a costly, critical affair. Get it wrong, and the resulting yield rates will plummet. In general, it becomes more difficult to achieve each successive node shrink because coming up with the optics required to perform optical lithography on masks with feature sizes near to or less than the size of the light wavelength can be extremely challenging. It’s like trying to use your fingertip to draw a line smaller than the width of your finger, with each line successively thinner than the last.
As AMD was planning its move from 65nm to 45nm, it had to weigh several considerations. The change was not only about getting to 45nm, but also selecting an approach that could apply well beyond 45nm and recycle manufacturing assets. When it costs anywhere from $1 billion to $4 billion to build a fab plant for a new process technology, you want to get the most bang for your buck. For example, one Intel presentation from September 2007 (“Intel Silicon & Manufacturing Update”) notes than the theoretical percentage of fab equipment that could carry forward from 90nm to 65nm was about 90 percent; the move from 65nm to 45nm stepped up to roughly 95 percent. Contributing to the economy of Intel’s 45nm shift was the fact that the company persisted in using 193nm dry lithography for its critical layers. Migrating to immersion lithography, a technique Intel is already using on its early 32nm SRAM chips, would have mushroomed critical layer lithography costs by over 25 percent.
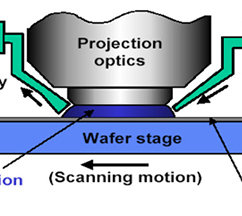
Who Says Water and Electronics Don’t Mix?
By using a water layer to further focus a light beam, immersion lithography helped AMD migrate from 65nm down to 45nm fabrication.
However, AMD has a different set of goals and needs at this point, and the decision was made to bite the bullet and adopt immersion lithography now. This entails injecting water between the projection lens and the wafer’s dye layer. This focuses the projection by about 40%, effectively narrowing an already ultra-narrow light beam and enabling a smaller fabrication node. Despite Intel’s presentation, AMD insists that immersion lithography allows it to accomplish in a single pass what normally takes Intel two passes with 45nm fabrication, so it’s ultimately a more cost-effective approach.
“This is something we’ve been working on in conjunction with IBM for a number of years now,” says AMD’s Steve Demski, product manager, Server and Workstation Division. “But AMD will be the first company to use immersion lithography in mass production. You don’t need immersion lithography to do 45nm, but it is absolutely a physical requirement to use it to get to 32nm. So in one sense, we have a lead over Intel on that next-generation development.”
The shrink to a smaller fab node usually gives manufacturers two possible benefits. They can either scale to faster frequencies or improve power efficiency. With Shanghai, AMD opted for a middle path. At system idle, Shanghai draws about 35% less power than Barcelona. At a system level, that means about 8% less power. In large deployment applications, such as storage farms or cloud computing, where users typically have massive clusters of systems that may have high activity during the day but have limited activity overnight, this kind of power conservation can be very compelling. Meanwhile, at a time when Shanghai had been widely expected to debut at 2.4 GHz, AMD is announcing launch SKUs up to 2.7 GHz and expects to scale higher quickly.
“The technology and manufacturing team have done incredible work in bringing up 45nm silicon,” writes AMD’s Randy Allen, senior vice president, Computing Solutions, in a memo allegedly leaked through Polish site PCLab.pl. “In fact, the silicon was so healthy and the process so mature that this is the fastest AMD Opteron processor that has gone from first wafer to production parts. Our leading-edge immersion lithography technology helps enable us to deliver dramatic performance and performance-per-watt gains, second only for an AMD processor to the initial transition to AMD dual-core. Our original plan of record for ‘Shanghai’ was to launch at 2.4 GHz in the 75-watt ACP thermal band. We have been able to significantly exceed that frequency target, and the parts are drawing much less power at both full load and idle than we originally expected. We believe many industry watchers will be pleasantly surprised with what they see from AMD at launch.”

Who Says Water and Electronics Don’t Mix?
By using a water layer to further focus a light beam, immersion lithography helped AMD migrate from 65nm down to 45nm fabrication.
About Those Thermals
You may have noticed AMD starting to use a new power metric over the past year called Average CPU Power, or ACP. The conventional Thermal Design Power (TDP) metric measures the maximum amount of power a computer’s cooling system can be required to dissipate when running real-world applications. According to AMD, ACP measures “processor power draw on all CPU power rails while running accurate and relevant commercially useful high utilization workloads.” The ACP spans power draw from the cores, memory controller, and HyperTransport links. To illustrate power draw situations, AMD states that ACP includes workloads such as TPC-C, SPECcpu2006, SPECjbb2005, and STREAM.
“The results across the suite of workloads are used to derive the ACP number,” noted AMD’s Brent Kirby, author of the company’s ACP white papers, to DailyTech last December. “The ACP value for each processor power band is representative of the geometric mean for the entire suite of benchmark applications plus a margin based on AMD historical manufacturing experience.”
Citing work loads from synthetic benchmarks seems a bit odd for a real-world metric, but the need for a consistent load in order to obtain replicable results makes sense. AMD says that ACP is a superior metric for gauging high-load work environments like datacenters.
On the other hand, we expect to see more apps like GridIron’s Nucleo Pro 2 reach the market. This background video rendering utility gains its fame from being able to approach 100% utilization across all cores without impairing foreground application performance. Given that, we would caution resellers not to ignore TDP specs, which will be more applicable in top-utilization scenarios. AMD has indicated that it will provide both numbers on its CPU products.
The TDP profiles for Shanghai remain unchanged from Barcelona, with the increase in cache circuitry and frequency more or less counterbalancing the energy savings from the fab shrink. This similarity lets us come up with a quick cheat sheet for translating ACP and TDP: 68W TDP equals 55W ACP, 95W TDP equals 75W ACP, and 120W TDP equals 105W ACP. For the sake of honesty and accuracy, be sure to keep these two metrics straight when comparing Shanghai against alternatives from both AMD and Intel.
That all said, Shanghai improves on Barcelona’s power savings story in two key ways. First, there’s the benefit gained from the move to 45nm—a 35% savings at idle, as stated above. But AMD also saves up to 21% in comparison to Barcelona through another new feature called AMD Smart Fetch.
“Even as a CPU is doing work, there will be periods where it’s waiting for data or instructions to arrive from the system,” explains AMD’s Demski. “Basically, you can set this up in the BIOS. If the CPU is waiting for data—I think the default is 16 clock cycles or 16ns—it’ll flush the contents of the L1 and L2 cache out to the L3, then it’ll shut down the core along with its L1 and L2.”
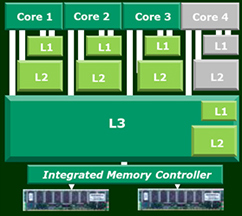
Finding Balance.
AMD’s Smart Fetch blends performance with power savings by flushing the L1 and L2 caches into L3 so that their contents stay available but the CPU core tied to them can power down when not needed.
Now, recall that Barcelona had a 2MB shared L3 and Nehalem (in the Core i7 version) has an 8MB L3. Intel opted to make its L3 inclusive, meaning that the contents of every L1 (32KB) and L2 (256KB) gets replicated in the L3. The purpose of this is to save on snoop traffic. When core #1 wants a piece of memory data, it first polls its own L1, then L2. If a miss occurs at L2, a search of an inclusive L3 will reveal if any core’s cache holds the data; if not, the request goes out to system memory. With an exclusive L3, as Barcelona uses, core #1 must “snoop” the caches of all other cores after an L3 miss before proceeding out to system memory.
This is one of those small but important differences that define which platform is better suited to a given application, depending on how it utilizes cache resources. The advantage of AMD’s exclusive L3 is that you get more cache to work with, and keep in mind that Barcelona and Shanghai both feature L2 caches twice the size of Nehalem’s. Shanghai delivers 8MB of total cache, and the system gets to use all of it, whereas Nehalem shaves off over 1MB of L3 (double this for eight-core designs) simply for data duplication. Moreover, Demski maintains that “snoop traffic is almost on the noise level in a two-socket system. It does get more appreciable as you go to four- and eight-socket systems.”
In any case, Smart Fetch represents a sort of hybrid between inclusive and exclusive L3. L1 and L2 data from any given core doesn’t get replicated into L3, but it can be migrated to L3 in order to shut down unneeded cores and not incur the power penalty of waking them up when their caches need to be snooped.
Other Innovations
Some aspects of Shanghai are predictable steps up the standards ladder. For example, the integrated DDR2 controller, backed by Barcelona’s Memory Optimizer Technology (sub-division of memory channels, larger memory buffers, optimized paging algorithms, etc.), now hops from DDR2-667 to DDR2-800 support. The core prefetchers that shuffle data directly into L1 in order to decrease latency have been improved again in Shanghai, and the core probe bandwidth has doubled.
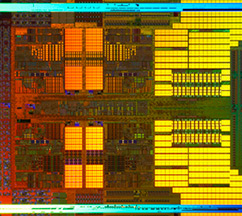
Four Cores Up Close.
This is Shanghai’s die shot. Note the increase of real estate devoted to cache memory.
The HyperTransport link gets a big boost under Shanghai. Today’s Barcelona-based Opterons use 8.0 GB/sec HyperTransport. The debut Shanghai models will carry this forward, using multiple links to get the necessary bandwidth. But in the second quarter of 2009, look for Shanghai to slip into HyperTransport 3.0, doubling the link bandwidth to a maximum of 17.6 GB/sec.
To return for a moment to Shanghai’s cache, AMD also introduces a new data integrity feature fetchingly called L3 Cache Index Disable, also due to come online in 2009 once select operating systems support the feature. The idea is that with more physical cache comes the potential for more physical cache errors. If the OS is continually doing ECC corrections on a certain section of L3 cache, Shanghai can automatically shut that area down. The L3 is divided into 16 sections, and AMD will allow up to two of those to be turned off. There will be a slight performance hit because the chip is losing part of its cache, but this will be counterbalanced by a reduction in error corrections. If the feature is implemented properly, the user should be able to detect the fault and have the CPU swapped when convenient. Meanwhile, L3 Cache Index Disable provides a slightly higher level of reliability over Barcelona.
“When you combine all of this with the aggressive pricing Shanghai will offer,” notes AMD’s Allen in his leaked memo, “we like how we are positioned to go after the high-volume 2P server market in addition to further reinforcing our leadership position in the 4P and 8P market. Shanghai is planned to deliver enterprises unparalleled price/performance and set new performance records for the most critical and demanding server workloads. And just like AMD set the standard for power-efficiency in the datacenter starting in 2003 with the launch of the original AMD Opteron processor, we should do the same with what is driving much of the server growth today—virtualization.”
In virtualization, a large part of the performance picture centers on how quickly a system can switch between virtual machines, or “worlds,” and how memory gets accessed is critical in this process. When an application tries to access a memory address, a memory management unit in the CPU monitors the process. If the page isn’t where it’s supposed to be, the memory management unit generates a page fault interrupt. At best, the operating system then tries to resolve the problem; at worst, the program crashes.
To deal with this issue, virtualization typically uses shadow page tables, meaning one page table visible to hardware and maintained by the hypervisor and one invisible to hardware used by the guest operating system. However, because of the extra processing involved in running the hypervisor, shadow page table faults can consume up to 75% of the hypervisor’s time. The optimizations AMD bakes into its modern processors (AMD-V), including Shanghai, virtualize the memory management unit and cache the mappings between the guest OS and physical hardware in order to drop virtualization overhead.
Another performance killer in virtualization is swapping. Swapping, or “world switching” is the process of each virtual machine taking focus of the hardware for the split-second that it runs its instructions. It has to take control of the memory, flush out the data, load its memory, process commands, and then make way for the next virtual machine. Barcelona’s Rapid Virtualization Indexing (RVI), which carries forward into Shanghai, dedicates a given area in RAM solely to one virtual machine. This way a sort of tunnel can be punched straight through the hypervisor, allowing the virtual machine to directly address the physical resources and avoiding the latencies of caching and swapping.
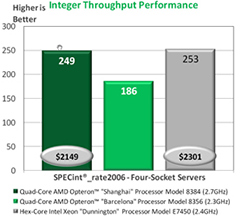
Weighing Performance and Price.
AMD’s internal benchmarks on integer performance—traditionally an Intel strength—show Shanghai now at parity with its Hapertown competitor, only AMD has a notable price advantage.
On top of all this, Shanghai breaks new ground with something called tagged, or guest, TLB. The translation lookaside buffer is a component of the CPU’s memory manager designed to assist and accelerate virtual address translation. Tagged TLB functions much like an L2 cache for the primary TLB. Both RVI and the tagged TLB help to accelerate world switching. With Barcelona, though, AMD didn’t have enough space to cache all of the virtual-to-physical memory translations generated by RVI. Tagged TLB under Shanghai provides extra room to cache more of that translation string, so there are fewer memory lookups needed for virtual machine-based applications. All in all, AMD states that world switching times improve under Shanghai by up to 25% versus Barcelona.
Also keep an eye on Shanghai’s virtualization performance from a power standpoint. AMD’s internally run tests on the Barcelona 8360 SE versus the Intel X7350 found that, given a constant workload across the same number of virtual machines, Barcelona used roughly 20% less wattage. Shanghai will only improve on Barcelona’s performance-per-watt equation.
Shanghai...Draw!
In a gun fight, you can’t afford to miss. The Barcelona launch hurt AMD; there’s no getting around that. But the company has struggled and planned, taken a deep breath, drawn itself up to face its adversary, and is now ready to pull the trigger. AMD knows it can’t miss this time, and it shows. Shanghai was supposed to launch in the first quarter of next year; instead, we’re getting product shipping in November.
AMD has released a handful of benchmark results already, but this isn’t the place to go over them. Of course, they look good. So do Intel’s. They always do. We’re firm believers in testing both platforms and seeing which works best for all of your customer’s needs. A simple benchmark graph is not going to tell you that. There are always other pressing concerns to round out a value equation, not least of which is the client’s existing and future infrastructure.
Stay Tuned.
You can look forward to Shanghai’s successor, Istanbul, in 2009. The processor will feature six cores and carry forward all of Shanghai’s improvements.
“People are always cautious with their money, but in the current fiscal environment, they’re even more cautious,” says AMD’s Demski. “We view Shanghai as being a really low-risk upgrade from something people are already familiar with, whether it’s the dual-core or Barcelona. But they have a system they’re using. They can either go the Nehalem path, which is all brand new—new chip, new chipset, new memory, new platform, new software. Everything is brand new, and in some instances it may achieve some impressive performance gains. But you also have to rip up the floor plan of your IT infrastructure and redesign around Nehalem, whereas Shanghai is a very evolutionary approach. The software you use today is going to work just as well and better on Shanghai. The systems you have today, you don’t have to worry about your cooling or your power delivery. It’s all going to just plug in and work. Shanghai will provide very good gains over Barcelona but also provide those gains without causing any rift to the business.”
With Shanghai, AMD is back in the game, and it’s time to take notice. With Opteron SKUs available today and Phenom parts sure to follow shortly, there are many applications and customer segments waiting to take advantage of Shanghai’s new benefits. Try the new processor out in your back rooms, learn its many strengths, and impress your customers.
RAMPAGE
OK, OK. I know you need another reminder about the economy like a .38 round to the frontal lobe. It’s all bad. Since my last RAMpage column, the media’s verbiage has shifted from “downturn” to “recession” to “The Great Depression, Part 2.” Now, regardless of how much of the mania you believe, we can all agree that these holidays are not going to be as rosy-cheeked as the last holidays (unless it’s from having your power shut off), and 2009 seems very likely to be more challenging than 2008.
We the channel need some help. Now. At a time when bailout and stimulus packages are raining like frogs in a Biblical plague, where’s our bailout?
Where are the top vendors stepping up to say, “Times suck, but we’re still making decent margins and have enough reserves in cash to fund at least three weeks of war in Iraq. We may have to lay off some people, but we know who our friends are in the channel, and we’re going to help them pull through this fiasco because that, in turn, is what’s going to help us come out stronger on the far side of this economic whatever-it-is.”
Let’s look again at the Rich Creek 2 example. The market is awash with notebooks, many of which now use Intel’s Montevina (a.k.a. Centrino 2) platform. But the only way to get the far more serviceable and modular Rich Creek 2 is through the channel. Not a single tier-one OEM today sells RC2. The platform is a unique, high-value advantage for the channel.
And on the Microsoft side, delivering unique value for the channel, we have...? A special edition of Windows? Uhh, no. Some Windows bundle with other worthwhile software (no, not MS Works and Arthur’s Teacher Trouble)? Even if such a bundle does exist as a distributor promotion, it won’t come remotely close to the pricing major OEMs get. And hey, all you Twilight Zone fans, wanna see something really scary? Go check out www.windowsoffers.com. Until last month, you could buy a laptop with Windows and get a free six-month subscription to BLOCKBUSTER Total Access. Never mind that there’s about as much chance of a whitebook with Windows installed qualifying for this promo as the crazy guy in the airplane has of catching that gremlin on the wing. Apparently, only tier-ones are allowed.
Before the Microsoft PR police come knocking, allow me to direct your attention to www.localpcbuilder.com, where you’ll find some very cool incentives for people to buy their Vista PCs from local system builders. Three years ago, when I first saw this site, Microsoft was pumping XP by giving away copies of (no, I’m not making this up) Nolo’s Encyclopedia of Everyday Law. This almost sounds like a failed joke meant to tie in with Microsoft’s anti-piracy efforts. By contrast, the site’s current promos for customers when they buy Windows or Office with a locally built PC sound downright magnanimous.
A DPR-1260 wireless print server from D-Link could come in handy as an 802.11g bridge if nothing else. When a customer buys Office Pro or Small Business 2007, he or she also qualifies for a free HP Photosmart printer, although I sure couldn’t figure out which model. Windows SBS buyers get a Palm Treo 700wx or Treo 750, which would have been really cool 18 months ago. With Windows Vista Ultimate the customer gets—after going through all the rebate business—LapLink PCMover, a Maxtor OneTouch 4 Mini 80GB drive, a D-Link GamerLounge 108G router, D-Link’s Wireless Pocket Router/AP, and the somewhat ambiguous HP Photosmart, plus a $50 rewards check good for any non-Microsoft product at your shop.
I assumed that this offer would only apply to the retail versions of Windows, but no! I ran the model numbers and found that OEM versions qualify. The OEM version of Ultimate runs $179.99 on NewEgg. Even if the Maxtor drive is only worth $50 to the user (and the lowest price I can find online now seems to be about $80), combine that with the check and the customer is paying $80 for Vista Ultimate, getting other knick-knacks for free, and has a $50 incentive to return to your shop to buy more stuff.
I won’t deny it. That’s a good deal and a very friendly thing for Microsoft to do for its partners. But I’m not done here.
I know from being on the consumer and vendor side of things that free promos for cool products don’t pay off as much as you’d expect. A surprising number of buyers never file their rebate paperwork or circle back to use their coupons. The bigger problem is that even more buyers never get to learn about the promo. They only want to know one thing, the bottom line price at the register. About that pricing. First off, I’d like to send kudos to Microsoft for realizing how totally astronomical its pricing was on Vista at launch and doing something about it. If you recall, Vista Ultimate started out in January of 2007 at $399. Today, it sells on Newegg for $267.49, and the OEM edition is a comparatively modest $179.99. This resembles the dive that Vista Home Premium took from an original $159 to today’s $119. The OEM version is only $99.99, and why the 3- and 30-packs cost more per unit on Newegg is beyond me.
Free Windows? Almost.
Depending on how you assess the value of Microsoft’s Buy Local Bonus Packs, users could feel like they’re getting the cost of Windows covered by promotional extras when they buy from your shop.
All of this sounds fantabulous until you realize that, as the New York Times reported in 2007, Microsoft has an emerging markets bundle of Windows XP Starter, Office 2007 Home and Student, Windows Live Mail Desktop, Microsoft Math 3.0, and Learning Essentials 2.0 for only $3. Yes, three US dollars—less than the cost of an espresso drink. Supposedly, this is to combat the prospect of pirated copies floating around China and Russia for only $1.
Covering the World With Windows.
Is it fair that Microsoft is willing to give away Windows for only $3 to emerging markets while U.S. system builders are left with little leverage in their markets?
Am I saying that Microsoft should slit the throat of its greatest cash cow and practically give away Windows across the world? No. Well, maybe a little bit. Clearly, selling Windows for $3 isn’t about getting rich, so it must be about securing market share. Fine, let’s talk about market share. W3Counter.com showed desktop Linux share up from 1.25% in May of 2007 to 2.02% in March of 2008. Is that increase coming from troglodyte hobbyists? Hardly. According to BBC News, Michael Dell himself uses the increasingly popular (and totally free) Ubuntu Linux distro on his Precision M90 laptop. Dell started selling PCs with Linux pre-installed in 2007 and now ships them around the world.
Linux comes pre-installed on most of the shockingly popular ASUS Eee PC machines, and you can expect it to be the de facto choice for ultra-low-end student notebooks like the Classmate PC. Oh, and I’ll go way out on a limb to posit that if the economy should run into real trouble (ahem), people struggling to pay their bills might opt for a free OS rather than one that is now generously discounted to between $100 and $300. In 2005, IDC stated that Turbolinux held 25% desktop share and 62% server share in China. How bad does a first-world economy have to get before it starts looking for the strategies that are helping third-world countries to thrive?
I’m not going to be another voice raised in premature or probably futile effort to predict the death of Microsoft. The titan continues to prove its resourcefulness and tenacity over time. But I will predict that at least the next few years will be harder for everyone, Microsoft included. The rules are changing. If not for the ongoing march of support resources toward Vista, I probably would have reverted to XP long ago for its greater usability. (As it is, two of the three PCs in my house still run XP, and there isn’t a single reason to change them.) I don’t know anybody who needs Vista. I’ve even abandoned Vista Search in favor of Google Desktop because Microsoft willfully ignores my thousands of WordPerfect files.
One Size Shouldn’t Fit All.
Vista Ultimate is a very popular version of Microsoft’s OS, but is it so strange to think that there could be a Windows version specially crafted for channel resellers with features that play to the channel’s strengths and capabilities?.
There are so many reasons for users and resellers alike to desire Microsoft alternatives. Usually, those are ideological or technical reasons, but now we can add economical reasons as a significant force, and that changes things. Now the onus is on Microsoft to step up its game. When gamers, IT managers, media enthusiasts, and grandmothers can all get what they need from Linux, Google, Mac OS, or whatever for less money, the laws of nature in a bad economy will change. The old Windows/Office paradigm may well break down.
The trouble with this prospect for the channel is that those alternatives offer little to no margin opportunity. Microsoft will lose share, and the channel will lose money. Microsoft needs to follow Intel’s example and do more than cut prices and offer a few incentive trinkets. It needs to come out with affordable and superior-value products specifically for the channel, products that a reseller with personal touch can educate buyers about. Like what? I don’t know. How about “Vista Business Plus,” which would feature a bunch of integrated management features that tie into a micro-business edition of System Center Essentials? How about a version of Home Server that ties into a subscription-based storage service run at the reseller’s site? Stuff like that. Stuff that requires real interaction with local experts, not some first-level, outsourced arm of a big OEM.
I recognize that the channel needs Microsoft. We need the margin and revenue streams Microsoft can help make possible. But Microsoft needs to give more credence to how the channel can help promote and spread its products. This is not a time for lip service. Microsoft needs to help give the channel more unique value, as Intel does, and leverage the channel’s unique abilities across all sectors. Clearly, the go-it-alone philosophy will be detrimental to Microsoft in a bad economy. Cooperation may be one of the few things that help us make it through to the other side intact.
Feature Story 1
With all the hype and buzz around solid state drives (SSDs) over the last few months, you’d think that hard disk technology, that old relic of magnetic particles and LP-like spinning platters, was already dead and buried. But the reality is that hard drives still own the vast majority of today’s storage market. Market analysis firm Web-Feet places the SSD industry at $7.5 billion in 2012. In a declining market, Seagate did $3 billion in just the third quarter of this year alone. Hard disks aren’t going anywhere anytime soon. The question is: What storage opportunities could you be missing right now because you’ve turned a blind eye to what’s new in hard disk technologies?
Hard drives aren’t sitting around waiting to die. Manufacturers continue to innovate with disk technology, and more value continues to pour into the format, making it ever more attractive to buyers. If you’ve felt like hard disk storage is flat and boring, just a matter of dollars and megabytes, then it’s time to take a fresh look. Hard drives have an increasingly strong story to offset the SSD buzz that’s about a lot more than pricing. If you’re not aware of this whole story, then you’re missing out on a lot of sales opportunities.
There are three top reasons to buy a solid state drive: ruggedness, power savings, and performance. Anyone who’s even brushed up against an SSD knows this, but the case for hard drives in SSD’s back yard may be stronger than you suspect. Know the details and you could have a lucrative competitive advantage.
Ruggedness
True, SSD wins this one, but perhaps by less than you think. Getting an accurate read on shock and vibration is made difficult by the fact that different vendors adhere to different methods of measurement. A “g-force” (commonly written as G) is a measure of acceleration, which seems counter-intuitive because we use it to refer to a drive coming to a very sudden stop. The acceleration caused by Earth’s gravity at the planet’s surface (1 G) is 9.8 meters per second per second, or 9.8 m/s^2. Most people will black out when subjected to sustained 7 G. A car traveling at about 60 MPH will experience 100 G when hitting a brick wall, and a baseball being struck by a bat chimes in at 3,000 G.
Now consider that today’s SSDs boast a shock rating of 1,500 G, a number that’s roughly equivalent to dropping a drive from a 27-foot height. When we asked one SSD manufacturer if its drive could really withstand this—not just the flash modules but the entire drive, including housing and plastic connectors—we were met with waffling. Moreover, the key failure point in notebooks due to shock is not the drive but the screen.
One Ring to Ruin It All.
See that circle gouged into the platter under the read/write head? That’s what a head crash looks like, and the odds of recovering data from those areas is roughly nil.
This wasn’t always the case. In the days before hard drives had accelerometers and parking ramps, it didn’t take much of a bump to cause a “head slap” or “head crash,” when the drive’s read/write head would be jarred into making contact with the underlying platter. If the platter was spinning, this would gouge a rut into the surface and damage the data in those tracks if not outright destroy the drive. But in recent years, manufacturers have built in accelerometers, similar to those used to deploy automotive airbags. In a state of free fall, as when a system is knocked off a desk, the g-force drops to near zero. When the accelerometer detects this, it commands the head to retract up the drive ramp into a location away from the media.
If you swing a bat at a hard drive in operation on your test bench, the drive is probably toast. In operation, a drive like the Seagate Momentus 7200 FDE specs a 350 G shock tolerance at 2 ms, meaning the length of time between shock pulses, and 1,000 G at 1 ms. This latter number is generally considered the non-operational rating, meaning the drive is simply sitting. The platters may be spinning, but the heads are not floating over the media; there are no read/write operations in progress. As a point of comparison, the Seagate Barracuda V desktop drive from 2002 featured a 2 ms operating spec of only 63 G and a non-operating spec of 350 G. Clearly, hard drives have come a long way in just a few years.
Now, compare this to the 1,500 G rating on some SSDs. (Intel’s X25-M, a great drive by most reckonings, is one example of a current SSD with only a 1,000 G / 0.5 ms spec.) Is it possible for a drive to sustain a major blow while in operation? Sure, especially if it’s constantly being pinged with requests from the OS or background apps. But a well-managed drive will quite often be in a non-operational state, so we’re really comparing 1,000 G against 1,500 G, if only because most major drive accidents will involve a drop, and these should automatically park the heads. And remember, the PCB on a hard drive can crack just as easily as one on an SSD.
Above the Crowd.
The bulk of today’s SSD offerings are surprisingly mediocre, which is good news to hard drive vendors. Only a handful of SSD units, such as this model from OCZ, have been praised as exceptional by reviewers.
Power Savings
Back in June, Tom’s Hardware ran a very controversial story titled “The SSD Power Consumption Hoax: Flash SSDs Don’t Improve Your Notebook Battery Runtime – They Reduce It.” A month later, the site issued an “apology” because its testing methodology had been flawed (workload varied throughout the test runs, contributing to higher drain by the CPU and other components) and then reasserted that its original premise remained valid. “The truth is that more and more Flash SSDs will be increasingly efficient,” wrote the follow-up article’s authors, Patrick Schmid and Achim Roos. “But many conventional hard drives can also be more efficient than today’s Flash SSDs in the scenarios some of you were demanding: when providing data under a defined workload such as video playback or in idle until the notebook battery runs empty. . . .This is exactly what our initial article meant to say: Many Flash SSDs simply aren’t there yet.”
One of the most telling charts from this follow-up article has to do with streaming read I/Os per watt, the ubiquitous performance-per-watt rating that’s quickly becoming the new criterion of choice. Of the four hard drives tested, Samsung’s 320GB HM320JI scored 248. Solid state drives from Crucial, Mtron, and SanDisk fell into the 281 to 317 range—hardly a ringing triumph considering that reads are SSD’s strength. The lone star in this test is OCZ’s SATA/300 SSD, which pulled in a phenomenal score of 1391. This is what the authors mean by “yet.” SSD, when done right, has the potential to excel in these operations, but thus far the results have been generally mediocre.
One other point from this article is worth noting: average power draw during DVD video (on-drive VOB file) playback. The five SSDs tested by Tom’s averaged a draw of 1.24 watts. The four hard drives tested averaged 1.35W, and Hitachi’s 160GB Travelstar 7K200 scored a slim 0.8W, handily beating the SSD average. Similar results appear in lowest idle drive power draw, with the Travelstar 7K200 pulling down 0.7W at idle compared to the SSD average of 1.08 watts.
To learn why Hitachi fares so well in these power comparisons, we talked with Larry Swezey, Hitachi GST’s director of marketing for consumer and commercial hard disk drives. It turns out that Hitachi is now in its seventh generation of energy-saving drive designs. Starting with last year’s P7K500 and continuing with the current 7K1000.B 3.5" desktop drives, the company migrated the system-on-chip (SOC) used in its energy-sipping, 2.5" Travelstar drives over to the Deskstar line. Among other things, the SOC uses a more power-efficient drive interface and switching regulators instead of older linear voltage regulators.
Getting More With Less
Hitachi’s 7K1000.B delivers a full terabyte of storage but does so with remarkably low power consumption. Hitachi gets little credit for its energy innovations, but its drives continue to lead the field.
The 7K1000.B normally specs 6.2W for random reads and writes, 3.6W at idle, and 0.8W in both sleep and standby. However, the drive features two advanced power management modes. The first is called unload idle, and it involves unloading the heads to the ramp and shutting down the servo for a power draw of only 3.1W. The second, low RPM idle, is like unload idle but it also drops the platter rotation rate to 4500 RPM, yielding a 40% drop under standard idle to just 1.9 watts. The drive monitors usage and can switch into these modes dynamically and independently of any external storage controller. An idle mode savings of up to 1.7W may not sound massive, but when you consider that current ENERGY STAR 4.0 requirements mandate a 50W idle mode maximum for the entire system, the leeway of having an extra 1.7W in your power budget takes on new significance.
“Other people have taken the lower RPM approach,” says Swezey. “That’s valid. It works well in external storage, where you’re limited by the speed of the USB bus. But the whole world is used to a certain level of data transfer, and that’s directly related to how fast the I/O is coming off the drive. We set out on both our 2.5" and 3.5" lines to give people the option to go to higher performance, higher spin speeds, but not make them pay for it with higher power consumption. We did a tremendous amount of work in the electronics channel design, the motor drivers, and so forth to get you there. For example, we now have a 7200 RPM drive with about .1W difference from the industry average 5400 RPM drive.”
Running MobileMark 2002 (Patch 2) over four hours, Hitachi’s own benchmarks show an average power consumption for the Travelstar 7K100 of only 0.96 watts. Stepping down to the 5K100 (5400 RPM vs. 7200 RPM) gets you down to 0.77 watts. Now, true enough, an SSD like Intel’s X25-M specs an active draw of 0.15W and an idle of 0.06W—a serious delta compared to hard drives. Even a new, leading drive like Hitachi’s just-released, 500GB Travelstar 5K500.B can only get read/write power consumption down to 1.4 watts.
When Energy Matters
Perpendicular recording has evolved enough to let units like Hitachi’s 5K500.B boast 500GB of capacity. When buyers need to save watts, why not opt for 2.5” drives like this that still provide plenty of storage?
There are two take-aways here. On one hand, we can see that, going forward, well-made SSDs will outstrip hard drives on power savings. On the other hand, real-world tests show that exactly how the drives are used and evaluated can have a tremendous impact on actual power draw, and the picture rarely looks as good for the average SSD as it does for the average power-conscious hard drive. Bring price back into the picture.
But power savings on hard drives don’t stop there. Most independent reviews set up a test configuration, run the benchmarks on one drive tethered to the integrated controller, and then simply swap drives into the same system, which is often a notebook because that’s what makes sense in a consumer environment that would compare SSD against HDD. What if we consider the advantages of modern power savings technologies applied to hard drives at the controller level? After all, 2.5" drives are increasingly being used in server solutions, and in environments where capacity and power matter more than raw platter performance, a drive like Hitachi’s E5K500.B (identical to the consumer drive but modified for 24x7, enterprise-class availability) makes excellent sense.
Power, Part 2: Saving the Server
Of all the major storage card manufacturers, Adaptec has been the most proactive about going “green.” With its new Series 5 and Series 2 cards, the company now supports a feature set it calls Intelligent Power Management, which can allegedly cut hard drive power consumption by up to 70% without impacting performance. Intelligent Power Management is based on a set of command codes built into the “SATA II” specs and which are currently being submitted for inclusion in the SAS specification. Whereas disk drives have conventionally either spun their platters at full RPM rates or stopped them dead, these codes allow for drives to spin at reduced RPMs in a standby mode. We all know the lag time involved in spinning up a drive from standby—sometimes it can take up to 30 seconds. Particularly in a server situation, this can be a tremendous hit on efficiency. But it takes far less time to spin up to 7,200 RPM from, say, 4,200 or 5,400 RPM than from a dead zero. The slower speed preserves performance while saving considerably on energy consumption.
It seems incredible that no other storage controller manufacturer has sought to leverage these lower RPM codes, but thus far Adaptec seems to be the only one doing so. According to the company, an average hard drive consumes 10W to 12W during normal operation at full RPM. In the power-off state when platters are stalled, consumption drops to 3 watts. In this new standby middle ground, drives use 5W to 7W and require only about one-third the time to spin back up to full speed.
Intelligence on a Budget
Adaptec’s Series 2 RAID 2405 card may not have the high-end processing speed and high port counts of more expensive cards, but it still delivers all Intelligent Power features on a SAS architecture.
Adaptec tested many drives and offers a few real-world examples to prove its power savings. The Hitachi HDS721050KLA330 runs at 10.8W under full load, 8.7W at standby, and 3.3W at idle—not a massive savings, but a 19.5% savings from standby is nothing to sneeze at. You start to sense the true potential of standby in the Hitachi HDT25050VLA360, which goes from 10.0W at full speed to a remarkable 3.2W at standby, just a breath above the drive’s 2.3W idle mode. Clearly, Adaptec’s claim of 70% possible energy savings is no, um, idle boast.
Standby mode obviously offers a lot of performance vs. energy savings compromise, but Adaptec goes further by equipping its storage management software with the ability to dictate when any or all drives will be active.
“The target applications for this feature, for it to be most effective, are those cases where you have significant idle or down time,” says Jason Pederson, Adaptec senior product marketing manager. “If you’re just doing a daily backup, you may only need access to your drives for an hour or two during the day. The rest of the time, you don’t need to be running those drives or have them spinning. Data from two years ago? You rarely access that, so it can be offloaded to a separate server with drives that can be spun down. Even with a file server, there’s significant time on the evenings and weekends when those drives can be spun down to save customers money.”
Adaptec study numbers break down drive idle time by target application, showing that file and print server drives are 75% idle. Disk-to-disk backup systems twiddle their thumbs 80% of the time, and bulk email and media systems (think Yahoo! mail and photo sharing sites) have drives doing nothing 95% of the time. Data goes through high usage when it’s new, but after a couple of months it goes into a very long hibernation. Adaptec’s Intelligent Power Management prevents the unnecessary and frequent pings that wake the drives up by caching unnecessary messages on the storage controller and storing them until the 256MB or 512MB of cache is full. At this point, the card will dump the messages to the drives en masse so they’re only spun up once, then soon powered back down. A “verify” function can optionally spin the drives up periodically to confirm their health. Otherwise Adaptec’s software can keep drives quiet for many hours whereas conventional OS-based power management often sends queries every few minutes.
Degrees of Conservation.
Hitachi goes far beyond simple on/off distinctions in its power modes, and even lower RPM rates are only one of its options. This chart shows the full range of power states in the vendor’s current drives.
“The impressiveness of this,” says Suresh Panikar, director of worldwide marketing at Adaptec, “is that Intelligent Power Management allows for the identification of idle time and then makes good use of it by providing control to IT managers or systems integrators to put that policy in place, which then dictates the power consumption overall in a storage system over time. A discussion of momentary time would not be very interesting. On a weekly, monthly, annual basis, there you’ll see real improvement in power consumption and utility costs. And ANY drive available today should be able to show at least some improvement from using Intelligent Power Management.”
The industry normally figures a 1:1 ratio for energy consumption and cooling costs. In other words, for every dollar a drive consumes in electricity, it costs another dollar to cool that drive to recommended levels. Adaptec chose the more conservative ratio of 0.7. At a price of 10 cents per kilowatt-hour, drive power of 8W, and 80% idle time, Adaptec figures that six months of Intelligent Power Management can save $19 for every four drives. At 96 drives, that’s $457 in savings every six months, and so on. Even in the small office space where these numbers won’t equate to big dollars, the green message remains persuasive.
Obviously, with no spinning platters, Intelligent Power Management can offer little benefit for SSDs, although Adaptec is already making vague mentions about having something for that market in 2009. We should also note that Intelligent Power Management reduces another advantage of SSDs: noise. SSDs may be totally silent 24x7, but Adaptec’s technology definitely shaves a lot of cumulative decibels from storage servers. For anyone who has to work near such machines, the drop in total noise should be greatly appreciated.
Solidly in the Lead
Intel’s X25 solid state drives are another of the few models that show what NAND flash can accomplish in modern storage. The question is whether you can achieve better value with hard disk technology after assessing SSD’s price versus its benefits.
Performance
This isn’t the place to dig into the detailed underpinnings of SSD technology. (We covered that in considerable depth a couple of months ago.) For our purposes here, suffice it to say that single-level cell (SLC) solid state drives offer less capacity but higher performance than their more consumer-oriented multi-level cell (MLC) counterparts, and it’s important to keep the target markets in mind when making comparisons.
Without question, SLC solid state drives triumph on random read tests. The process of a hard disk having to perhaps spin up and then locate the heads precisely over the desired data before extracting it takes much longer than an SSD simply sending electrons between chips. Emerging SSDs boast 250 MB/sec read rates, but as we see so often on both sides of the drive fence, specs and real-world results rarely look the same.
One of the best comparative assessments we’ve seen to date of a performance-oriented consumer hard drive and solid state drive is Anandtech’s recent look at Intel’s X25-M. If nothing else, this roundup shows two things: The future for SSD looks very bright once prices come down, and there remain many, many situations in which hard disk technology is still the obvious choice.
Hey, SSD---Eat This
Western Digital’s VelociRaptor does a remarkable job of holding its own against SSD’s alleged performance advantages…and does so at a fraction of SSD’s cost.
Consider Anandtech’s PCMark Vantage tests, which seek to reflect real-world performance. The key hard drive to compare against is Western Digital’s VelociRaptor, a SATA-based screamer with 2.5" platters and a 10,000 RPM spin rate that’s generally targeted at gamers or businesses looking for a less expensive alternative to SAS. In the all-inclusive PCMark test, Intel’s drive scored 9044 to WD’s 6676—a 26% advantage for Intel. On the other hand, the 80GB X25-M is expected to carry a $595 price tag, $7.44 per gigabyte, versus $270 (current Newegg) for the 300GB VelociRaptor, yielding 90 cents per gigabyte. Now how persuasive is that PCMark delta?
Anandtech’s multitasking results were also intriguing. While extracting a 5GB archive, the author ran Photoshop after 30 seconds of extraction. The VelociRaptor scored 116 seconds to complete extraction, significantly better than Intel’s 161 seconds. However, launching Photoshop during this test took the X25-M only 12.2 seconds compared to 27.3 for the VelociRaptor. Again, this makes the point that the only way to really determine which technology and specific drive is best for your clients is to test them under the customer’s unique environment.
In general, it’s safe to say that SSD will win in random read tests while hard drives outperform in sequential reads, sequential writes, and random writes. For instance, Anandtech’s prior look at SSDs pitted the VelociRaptor against the latest 64GB SSDs from OCZ and Samsung (essentially the same drive). Performing Nero Recode 2 on a ripped movie, the VelociRaptor scored 124 to the OCZ and Samsung’s 128. Factor pricing back in, and the choice is obvious. In fact, consider implementing a two-drive RAID 0 with hard disks to further boost performance; you’ll still be far ahead compared to SDD in price-per-gig.
Need Another HDD Advantage?
As everybody knows, laptops are great items for thieves to make off with. As a professional, you know at any given time that you’ve got some fairly sensitive information on there. Yet for the most part, the level of security on a laptop in terms of whether someone can turn it on and have access to your data is woefully low.
Lock It Down
Seagate was among the first to pioneer on-drive AES encryption, and the Momentus 5400.2 FDE is one example of this feature in action today.
Back in 2007, Hitachi implemented what we call bulk data encryption on our drives. We build a 128-bit AES engine into the main drive SOC. So if a customer wanted us to ship them a drive with encryption enabled, we could do that. That ended up in a couple of major OEM notebooks. The beauty of it was that it’s a very high-level encryption engine that’s on full-time. It’s not using any of the software in the system or taking CPU time, but the big detriment of software-based encryption is you take about a 15% performance hit. That went away. As long as you had a BIOS that supported the traditional HDD password, you could set it, and the drive encrypted everything that came across the interface and decrypted everything that came back. In the unfortunate event that the system was stolen, there was absolutely no easy way—“easy” being anything short of using supercomputers for months to try to crack the encryption—to get at that data.
“Say you talk to a Morgan Stanley, and you say, ‘I’ve got this great drive encryption for you. It’s very safe, uses an AES engine, blah blah blah,’” says Hitachi GST’s Larry Swezey. “The guy says, ‘OK, but how can I prove that this is enabled?’ His problem is that if they lose a laptop and can’t absolutely show an audit trace to prove that the laptop did indeed have the encryption enabled, they can’t know with assurance that the data was protected when it was lost. Then we get letters telling us that at some point our valuable data was lost, we’ll pay for credit for a year, good luck.”
To the best of our knowledge, no SSD to date has incorporated full-disk AES encryption, which seems very odd given the high-end nature of the product today. This is just one more instance of a hard drive advantage that is often overlooked amidst all of the SSD brouhaha. We’re not saying that SSD won’t be king someday. But this is today, and in the wide majority of applications and user needs, hard disks still reign. The trick is to find the smart ways to prove HDD’s superiority, even over other hard disk competitors, and turn such advantages into profit for you.